背景
ETL数据处理常常都是运行时间很长的批处理job,实时性不需要很强,只需要定时执行就好了,Linux下的crontab是一个很不错的调度工具,但是没UI不直观, 搜索了一下,业界也开源了很多不错的调度工具,例如ariflow, azkaban ,oozie, 其中oozie是apache的项目,历史悠久,但是很啰嗦,太复杂,我的需求是:
- UI简洁
- 支持cron表达式
- 依赖管理与执行
几个调度工具的比较可以参考:https://www.jianshu.com/p/4ae1faea733b
Azkaban项目介绍
azkaban是linkin公司开源的一个项目,Java开发的,整体UI不错,文档有一些,个别不是更新很及时。代码结构组织很细,github code地址:https://github.com/azkaban/azkaban,
solo的安装已经够用了,
文档地址:https://azkaban.readthedocs.io/en/latest/index.html, 安装直接看文档就可以了。
HDFS插件的安装
HDFS作为分布式文件系统,其本身其实已经提供了一个浏览的工具,如果HDFS有安装在ano-lxspk200服务器上,浏览地址就是:http://ano-lxspk200:50070/explorer.html#/。
但是azkaban这个插件的优点是可以直接在UI上预览一下HDFS上文件的内容,如下图所示:
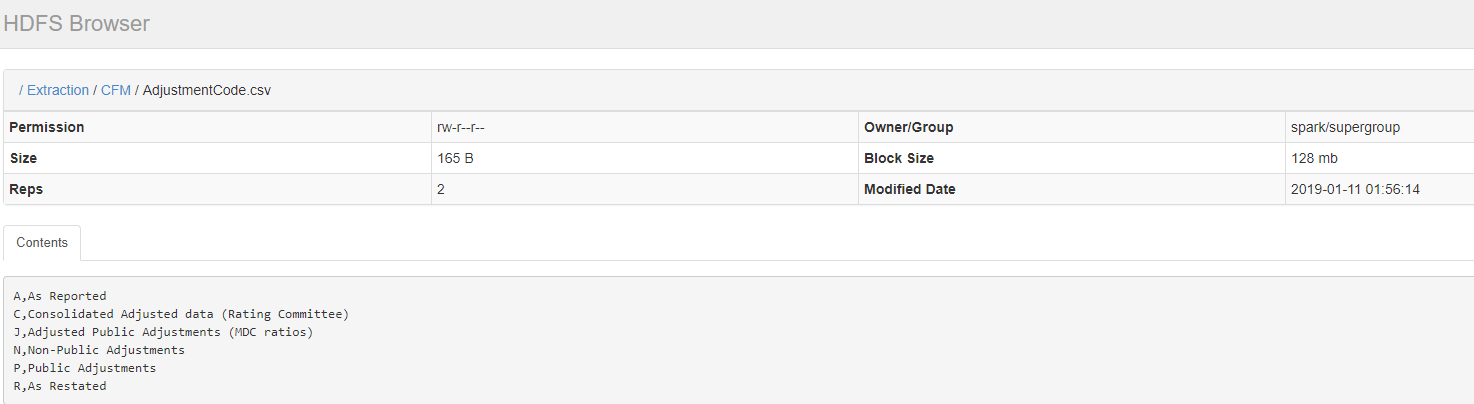
Github代码下载后,直接编译源代码安装:
cd azkaban; ./gradlew build -x test installDist cd azkaban-solo-server/build/install/azkaban-solo-server
添加HDFS插件的配置 vi conf/azkaban.properties
azkaban.hdfsviewer.plugin.dir=plugins/viewer/hdfs/
接下来就是插件目录创建和安装:
mkdir plugins/viewer
mkdir plugins/viewer/hdfs
mkdir plugins/viewer/hdfs/conf
cd plugins/viewer/hdfs/
cp -R ~/azkaban/az-hdfs-viewer/build/install/az-hdfs-viewer/lib/ .
vi conf/plugin.properties 配置内容如下:
viewer.name=HDFS
viewer.path=hdfs
viewer.order=1
viewer.hidden=false
#viewer.external.classpaths=extlib/
viewer.servlet.class=azkaban.viewer.hdfs.HdfsBrowserServlet
hadoop.security.manager.class=azkaban.security.HadoopSecurityManager_H_2_0
azkaban.should.proxy=true
proxy.user=spark
proxy.keytab.location=
allow.group.proxy=false
file.max.lines=1000
execute.as.user=false #这个其实已经没有用了
azkaban.native.lib=/home/spark/azkaban/azkaban-solo-server/build/install/azkaban-solo-server/plugins/viewer #这个目录需要放置execute-as-user二进制的可执行文件
其中execute-as-user是通过gcc编译此代码生成的:execute-as-user.c,编译后的文件放置/home/spark/azkaban/azkaban-solo-server/build/install/azkaban-solo-server/plugins/viewer目录下,如果没有gcc编译器,直接在此下载我编译好的execute-as-user.tar
注意: 我下载后的azkaban是放置在/home/spark目录下面,你们要根据自己的情况更改
gcc execute-as-user.c -o execute-as-user
最后启动jetty
azkaban-solo-server/bin/start-solo.sh
通过http://ano-lxspk200:8081/hdfs就可以访问了. 下面是目录列表以及需要添加的jar包
[spark@ANO-LXSPK200 azkaban-solo-server]$ tree extlib/
extlib/
├── commons-configuration-1.6.jar
├── hadoop-auth-2.6.1.jar
├── hadoop-common-2.6.1.jar
├── hadoop-hdfs-2.2.0.jar
├── hadoop-yarn-api-2.6.1.jar
├── hadoop-yarn-common-2.6.1.jar
├── htrace-core-3.0.4.jar
└── protobuf-java-2.5.0.jar
[spark@ANO-LXSPK200 azkaban-solo-server]$ tree plugins/
plugins/
├── jobtypes
│ └── commonprivate.properties
└── viewer
├── execute-as-user
└── hdfs
├── conf
│ └── plugin.properties
└── lib
├── aopalliance-1.0.jar
├── avro-1.7.4.jar
├── az-hdfs-viewer-3.66.0-12-gd617f7d.jar
├── commons-codec-1.7.jar
├── commons-compress-1.4.1.jar
├── guava-19.0.jar
├── guice-4.1.0.jar
├── jackson-core-asl-1.8.8.jar
├── jackson-mapper-asl-1.8.8.jar
├── javax.inject-1.jar
├── log4j-1.2.17.jar
├── mongo-java-driver-2.14.0.jar
├── paranamer-2.3.jar
├── parquet-avro-1.3.2.jar
├── parquet-column-1.3.2.jar
├── parquet-common-1.3.2.jar
├── parquet-encoding-1.3.2.jar
├── parquet-format-2.0.0.jar
├── parquet-generator-1.3.2.jar
├── parquet-hadoop-1.3.2.jar
├── parquet-hadoop-bundle-1.3.2.jar
├── parquet-jackson-1.3.2.jar
├── slf4j-api-1.7.18.jar
├── slf4j-log4j12-1.7.18.jar
├── snappy-java-1.0.5.jar
└── xz-1.0.jar